Was ist ATP und welchen Nutzen hat es?
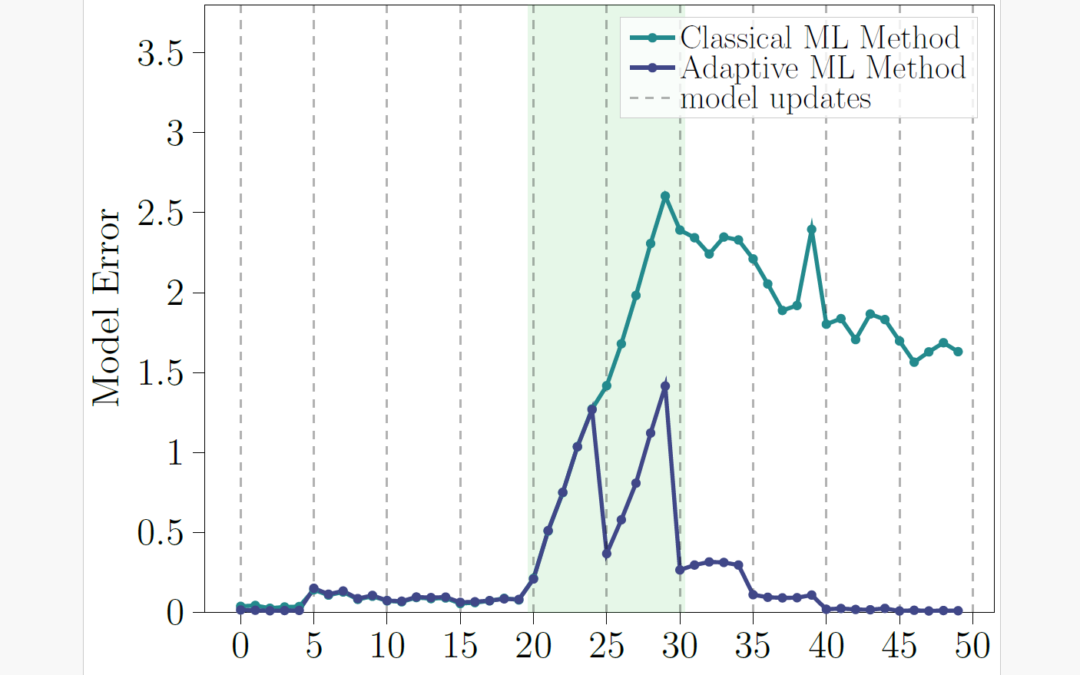
Im Kontext von sogenannten Long-Time-Buy- oder All-Time-Buy-Entscheidungen erstellt ATP eine Prognose bezüglich der Nachfrage nach Serviceteilen (vor allem in der Automobilindustrie). Solche zukünftigen Nachfragen können die nächsten 10-20 Jahre betreffen und sind schwer abzuschätzen, weshalb oft zu viel (ein-)gekauft wird. Daraus folgt, dass nach jahrelanger Lagerung letztlich große Menge verschrottet werden müssen, was hohe Warenbestands- und Lagerkosten verursacht. Diese können durch präzisere Bedarfsprognosen deutlich gesenkt werden. Die ATP-Lösung der IBM wurde genau zu diesem Zweck entwickelt: um mit hoher Genauigkeit die Allzeit-Nachfrage vorherzusagen.
Wie funktioniert ATP?
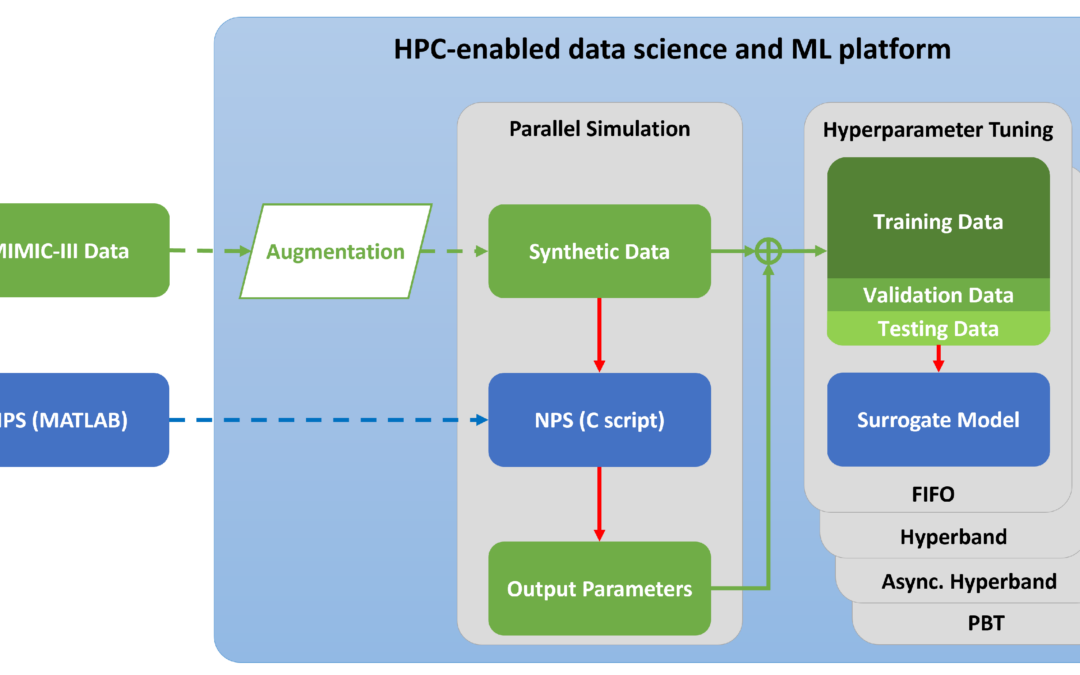
Die ATP-Lösung kombiniert verschiedene Vorhersagemodelle, damit die unterschiedlichen Bedarfsmuster von Serviceteilen (Fast Mover, Slow Mover, Non-Movers) berücksichtigt werden können. Das heißt: Teile, die einen vollständigen historischen Lebenszyklus durchlaufen haben, werden verwendet, um die Nachfrage nach denjenigen Teilen zu prognostizieren, die sich noch in der Mitte ihres Lebenszyklus’ befinden. Für sogenannte Slow Movers wird ein neuronaler Netzwerkansatz genutzt. Zur Identifikation des wahrscheinlichsten Lebenszyklus’ von neuen Teilen kommt hingegen eine Kombination aus Cluster- und Entscheidungsbäumen zur Anwendung. Die ATP-Lösung wurde mit Hilfe der IBM SPSS Modeler Plattform entwickelt, die zur Daten- und Ergebnisaufbereitung durch R-, PERL- und Python-Skripte ergänzt wurde.
Laufende und geplante ATP-Forschungsarbeiten
In Zusammenarbeit mit dem Karlsruhe Service Research Institute wird die ATP-Lösung kontinuierlich weiterentwickelt. Derzeit werden zudem zwei Masterarbeiten mit den Themen “ Planning the life-cycle demand of new parts” und “Predicting the future demand with vehicle production data” verfasst. Die zukünftige Forschung konzentriert sich einerseits auf die Verfeinerung der bestehenden Vorhersagemodelle und andererseits auf die Entwicklung weiterer kausalbasierter Vorhersagemodelle, insbesondere solche Modelle, die bekannte Fehlerraten berücksichtigen.
ATP und SDIL
Die Implementierung von ATP im SDIL ist aus mehreren Gründen für alle Beteiligten von Vorteil:
- Die ATP-Lösung hat sich bei mehreren Automobilherstellern bewährt, weshalb anzunehmen ist, dass die ATP-Demo einen realistischen Big Data-Anwendungsfall darstellt.
- Die Daten, die für die ATP-Demo verwendet wurden, sind anonyme reale Daten, die normalerweise nur erschwert zugegriffen werden kann.
- Die ATP-Demo beweist, dass die ATP-Lösung cloudfähig ist.
- Für weitere Forschung kann die ATP-Demo um neue Modelle erweitert und als Testumgebung für solche Modelle genutzt werden.
- Die ATP-Demo kann die Fähigkeit demonstrieren, eine analytische Lieferkette aufzubauen mittels IBM SPSS Modeler, kombiniert mit IBM SPSS CADS, Python und R-Komponenten.
- Die ATP-Demo verfügt über eigene Daten und ist, sobald sie im SDIL implementiert und getestet wurde, bereit für die Anwendung.
- Die ATP-Demo kann genutzt werden, um Kunden aus der Automobilindustrie für das SDIL zu gewinnen.
Erfolgsmessung
- Erfolgreiche Implementierung des ATP Demos, wie oben dargestellt
- Wie häufig wird die ATP-Demo bei einem potentiellen Kunden gezeigt?
- Wie häufig hat die ATP-Demo zu neuen Projektabschlüssen geführt?
- Konnten aufgrund mit der ATP-Demo neue SDIL-Teilnehmer gewonnen werden?
Data Innovation Community
Industrie 4.0
Projektpartner
IBM Deutschland GmbH, Karlsruhe Service Research Institute (KSRI)
Ansprechpartner
Dr. Peter Korevaar, peter.korevaar@de.ibm.com
Zeitraum
Jan. 2017 – Jan. 2019