Wie geeignet sind große Sprachmodelle für verschiedene Aufgaben in der Industriesoftware-Entwicklung? Unter Berücksichtigung der hohen Anforderungen an Verfügbarkeit und Sicherheit in diesem Bereich werden potenzielle Anwendungsfälle wie die automatisierte Erstellung von Testplänen und Dokumentationen untersucht, um effizientere Prozesse zu ermöglichen und damit zur Produktivitätssteigerung in der Softwareentwicklung beizutragen.
Projektziele
Die Entwicklung von Industriesoftware ist geprägt durch hohe Anforderungen an Verfügbarkeit und Sicherheit der Software. Neben dem Quellcode der entwickelten Software sind viele weitere Texte Teil des Entwicklungsprozesses: Anforderungen, Normen (z.B. für Kommunikationsprotokolle), Testpläne/-berichte und Quellcode für automatisierte Tests.
Daraus ergeben sich zahlreiche potenzielle Anwendungsfälle für große Sprachmodelle. Hierzu gehören beispielsweise die Erstellung von Testplänen ausgehend von Anforderungen, die Implementierung von Testfällen ausgehend von einem Testplan, oder die Erstellung von Dokumentation ausgehend von Quellcode.
In diesem Mikroprojekt soll auf Grundlage des Services Anpassung großer Sprachmodelle mit Unternehmensdaten (Fraunhofer IAIS) für diese und weitere Anwendungsfälle die Eignung von großen Sprachmodellen systematisch bewertet werden.
Projektergebnisse
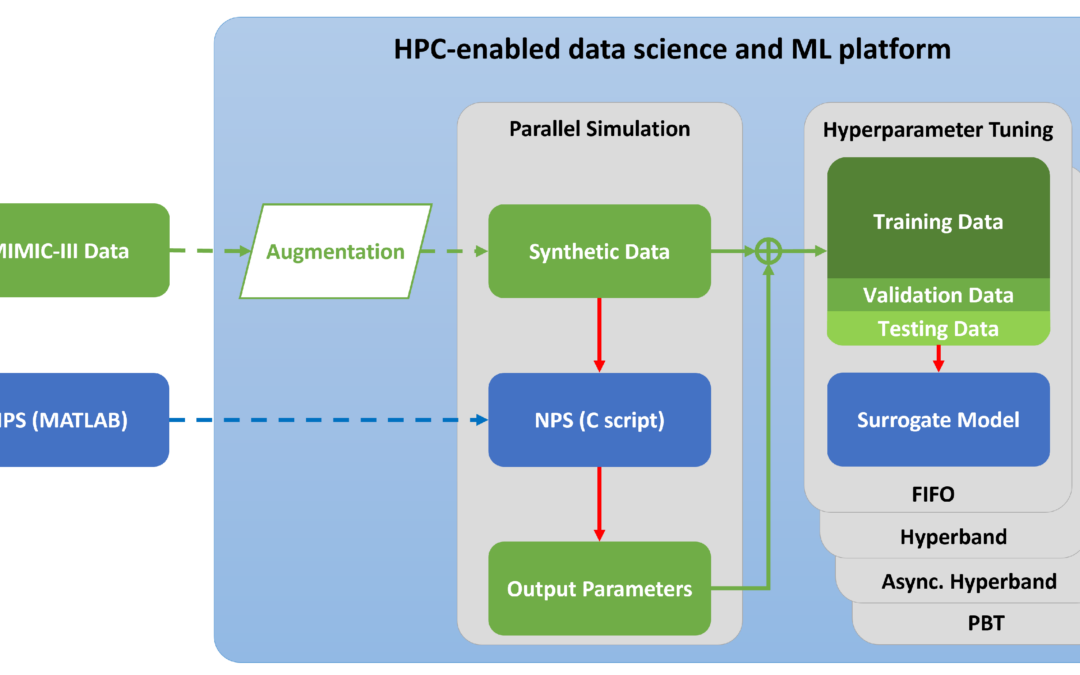
Für das Projekt haben wir eine Pipeline aufgebaut, bei der dem LLM Kontext, Anleitungsschritte und Beispiele für Generierung des Outputs zum jeweiligen Use Case mitgegeben werden. Nach der Generierung durchläuft der Output des LLMs eine Evaluationsschleife und bekommt einen Score, der die Qualität des Outputs bewertet. Ist die Qualität gut genug, wird der Output akzeptiert und an den User ausgegeben. Wurde die Qualität als zu schlecht bewertet, wird ein neuer Output generiert.
Für die Umsetzung der Pipeline haben wir auf GPT3.5 und GPT4 von OpenAI zurückgegriffen. Wir haben uns für diese Modelle entschieden, da sie ein gutes Verständnis von natürlicher Sprache als auch unterschiedlichen Programmiersprachen haben und sie mit Hilfe von gezieltem Prompt Engineering auf unsere Use Cases angepasst.
Wir haben festgestellt, dass die steigende Komplexität von Code-Ausschnitten und Anforderungen in Testplänen eine Herausforderung für die LLMs darstellt. Außerdem sind LLMs mit manchen Programmiersprachen und Frameworks mehr vertraut als mit anderen, wodurch sich Qualitätsunterschiede in den generierten Outputs bemerkbar machen können.
Dennoch können die LLMs in den von uns ausgewählten Use Cases die Mitarbeitenden gut unterstützen und den Arbeitsaufwand verringern. Dennoch ist die Anwendung eben nur zur Unterstützung der Mitarbeitenden gedacht und folgt einem Human-in-the-Loop Ansatz, bei dem die Mitarbeitenden immer noch die letzte Entscheidung über den Einsatz der generierten Ergebnisse treffen.
Nächste Schritte
Als nächste Schritte wollen wir die Evaluierungsschleife für unsere Use Cases um eine Feedback-Schleife ergänzen, die dem LLM neben einem Score noch detailliertes Feedback in Form von Stichpunkten und Hinweisen gibt, das konstruktiv für eine verbesserte Generierung genutzt werden kann. Außerdem wollen wir unsere Anwendung auf mehr realen Industriedaten testen, um weiter den Nutzen und die Limitationen von LLMs für unsere Use Cases zu evaluieren.
Projektzeitraum
15.11.2023 – 15.05.24
Förderung
BMBF-Förderung Mikroprojekt, SDI-S 2. Call (Laufzeit 2023/2024, Dauer ca. 6 Monate)
Projektpartner
Codewerk GmbH, David Barton & Fraunhofer IAIS, Dr. Joachim Köhler und Jana Germies