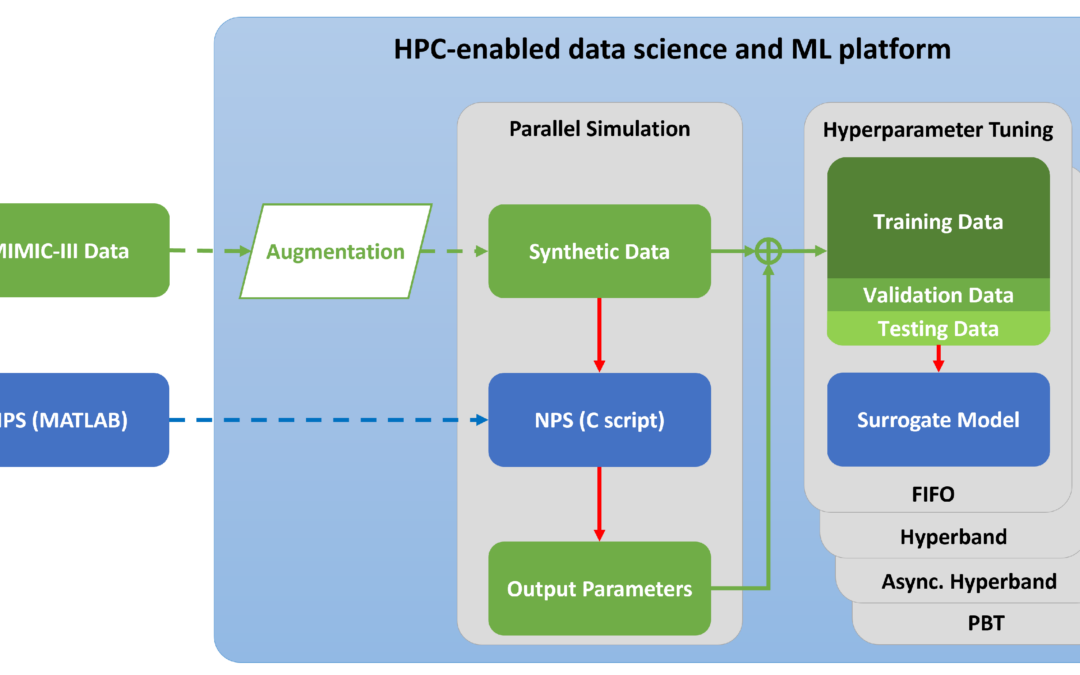
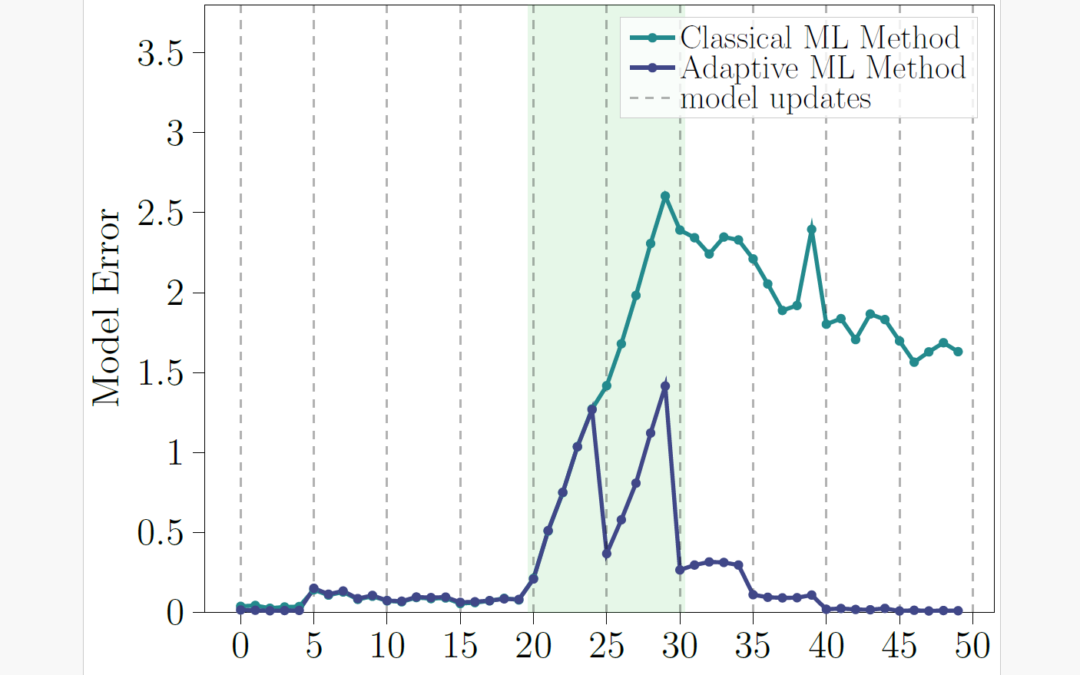
")
Der rasante technische Fortschritt im Bereich neuartiger generativer Sprachmodelle hat zum stark zunehmenden Interesse an der Nutzung konversationeller KI-Systeme geführt. Ein Risikofaktor aktueller Sprachmodelle ist die Halluzination von Informationen, bei der das Modell Texte generiert welche plausibel erscheinen, jedoch faktisch inkorrekt sind. Für die Anwendung in Suchmaschinen ist dies problematisch, in kritischen Anwendungen eine elementare Bedrohung. Während faktische Fehler aktuell noch erkennbar und Nutzer aufgrund deren Häufigkeit noch wachsam sind, könnte sich auf Dauer ein unberechtigtes Vertrauen gegenüber der Korrektheit generierter Texte einstellen. Durch die überprüfbare Verifikation und Korrektur der in generierten Texten enthaltenen Informationen soll daher die Vertrauenswürdigkeit von Sprachmodellen erhöht werden.
Der aktuell in Modellen wie ChatGPT verwendete Ansatz zur Verbesserung generierter Texte ist das Training von Modellen mittels menschlichen Feedbacks (reinforcement learning from human feedback, RLHF). Da dieser Ansatz nicht zwangsläufig nach faktenorientierten Kriterien optimiert, wird auf das Problem der Halluzination nur indirekt eingegangen. Die Weiterentwicklung immer besserer Modelle allein auf Basis von RLHF birgt die Gefahr, dass Modelle lediglich besser darin werden Fehlinformationen legitim erscheinen zu lassen, statt sie zu vermeiden. Zentraler Fokus des beantragten Projektes ist daher die Entwicklung und Evaluation von Methoden, welche die Ausgaben von Sprachmodellen fortlaufend auf ihre faktische Korrektheit prüfen und automatisch korrigieren.
Der vorgeschlagene Ansatz baut auf dem vorigen SDIL-Mikroprojekt von Aleph Alpha und dem KIT-AIFB auf: Die in diesem Rahmen entwickelten Modelle extrahieren strukturierte Informationen aus Texten mit Hilfe derer generierte Texte automatisch mit einem Wissensgraphen abgeglichen und so auf ihren Wahrheitsgehalt überprüft werden können (Verifikation). Anschließend sollen, im Falle einer Halluzination, Fehlinformationen über Wissensgraph-gestützte Dekodierungsstrategien korrigiert werden (Korrektur). Dieses Verfahren wird ohne weiteres Training auf vortrainierte Sprachmodelle angewendet, was Effizienz und Anwendbarkeit enorm erhöht, da das Training der Energie- und Kosten-intensivste Teil der Modellentwicklung ist.
Neben der Eindämmung von Risiken für Anwender ist die Entwicklung der vorgeschlagenen Lösungen auch wirtschaftlich höchst relevant: Für Unternehmen wie Aleph Alpha, welche auf Sprachmodellen basierende Services anbieten, ist es ein entscheidender Wettbewerbsvorteil über Modelle zu verfügen, die nachweislich wahrheitsgemäßer antworten als Modelle anderer Anbieter, insbesondere vor dem Hintergrund der EU-Richtlinien bzgl. künstlicher Intelligenz. Im Projekt kommen Sprachmodelle mit bis zu 200 Milliarden Parametern zum Einsatz, wofür die SDIL-Infrastruktur basierend auf den Erfahrungen des vorigen Mikroprojektes hervorragend geeignet ist.